
We investigate across four different factors of sensitivity in the downstream setup:
Models evaluated: We evaluate a suite of 9 recent video SSL models.
Video Datasets: We use datasets varying along different factors as shown in the radar-plot below.
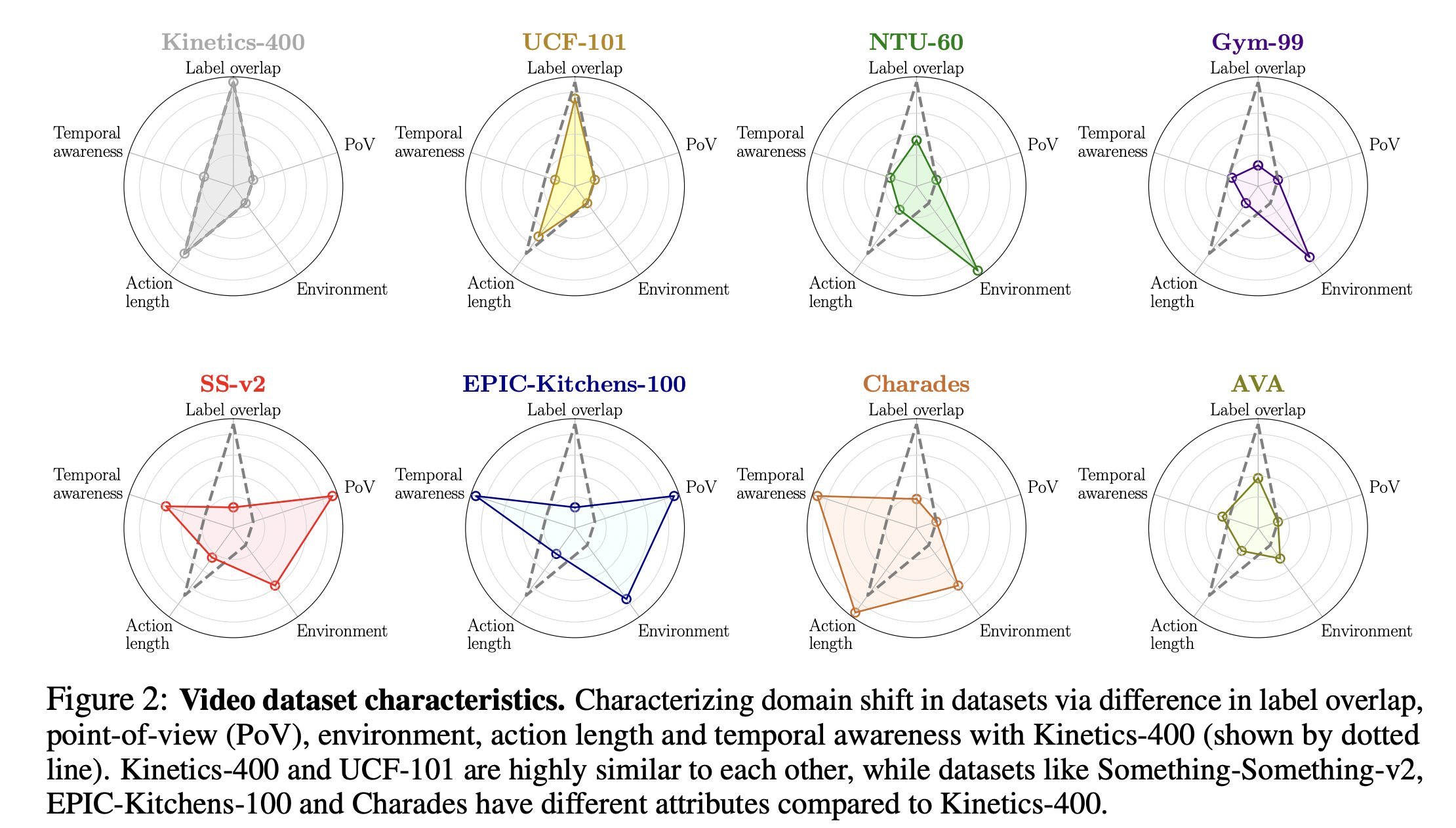
We summarize the key observations from our experiments below.
(See Table 1) Performance for UCF-101 finetuning and Kinetics-400 linear evaluation is not indicative of how well a self-supervised video model generalizes to different downstream domains, with the ranking of methods changing substantially across datasets and whether full finetuning or linear classification is used.
We observe from Fig. 3 that video self-supervised models are highly sensitive to the amount of samples available for finetuning, with both the gap and rank between methods changing considerably across sample sizes on each dataset.
Most self-supervised methods in Table 2 are sensitive to the actions present in the downstream dataset and do not generalize well to more semantically similar actions. This further emphasizes the need for proper evaluation of self-supervised methods beyond current coarse-grained action classification
The results in Table 3 reveal that action classification performance on UCF101 is mildly indicative for transferability of self-supervised features to other tasks on UCF-101. However, when methods pre-trained on Kinetics-400 are confronted with a domain change in addition to the task change, UCF-101 results are no longer a good proxy and the gap between supervised and self-supervised pre-training is large.
Based on our findings, we propose the SEVERE benchmark (SEnsitivity of VidEo REpresentations) for use in future works to more thoroughly evaluate new video self-supervised methods for generalization. This is a subset of our experiments that are indicative benchmarks for each sensitivity factor and realistic to run.
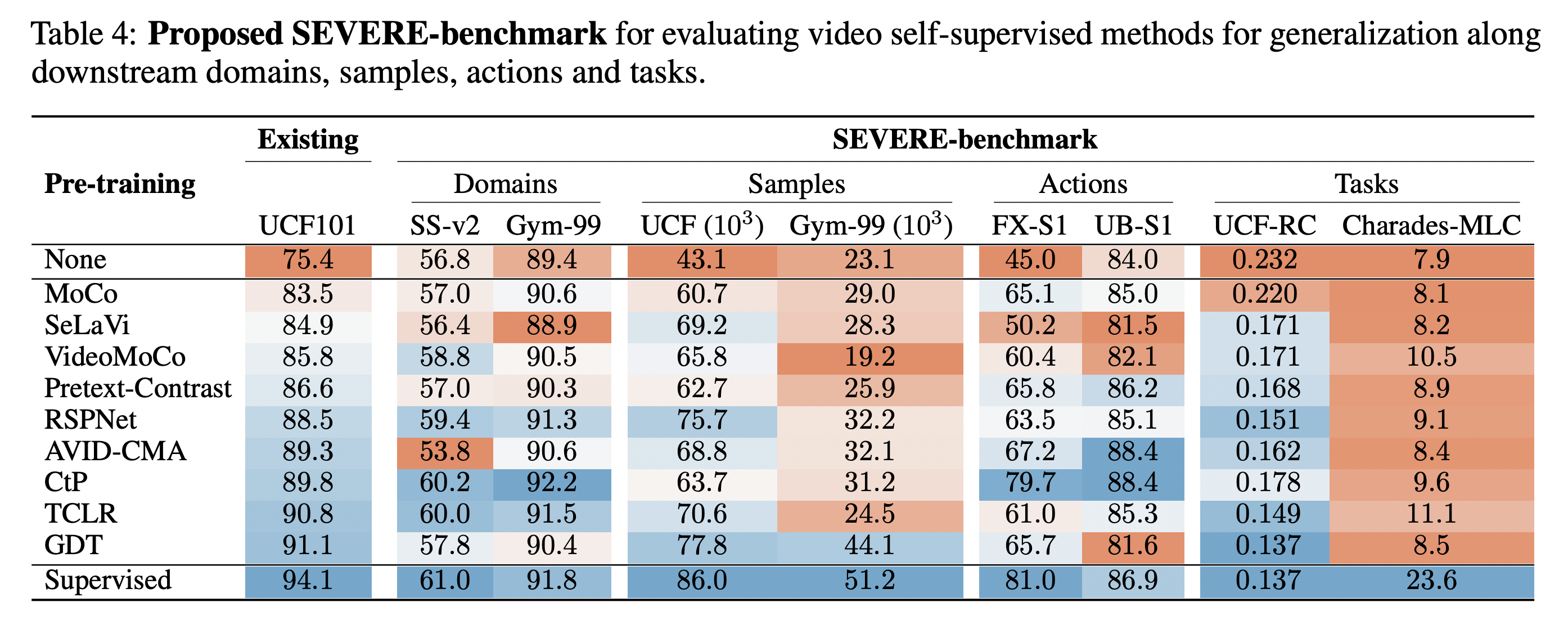
Please check out our code if you'd like to evaluate your self-supervised model on the SEVERE benchmark.
@inproceedings{thoker2022severe,
author = {Thoker, Fida Mohammad and Doughty, Hazel and Bagad, Piyush and Snoek, Cees},
title = {How Severe is Benchmark-Sensitivity in Video Self-Supervised Learning?},
journal = {ECCV},
year = {2022},
}